SpringAI技术记录-RAG和RAG增强扩展方案
本文最后更新于 2025-07-21,文章内容可能已经过时。请谨慎检查,如果谬误,请评论联系
由于Spring-AI和Spring-Ai-alibaba都在起步阶段,且在快速迭代,这里记录的内容基于以下版本:
<properties>
<java.version>23</java.version>
<spring-ai.version>1.0.0-M5</spring-ai.version>
<spring-ai-alibaba.version>1.0.0-M5.1</spring-ai-alibaba.version>
</properties>
阅读
SpringAI 模块化RAG的库: 检索增强生成 :: Spring AI 参考 --- Retrieval Augmented Generation :: Spring AI Reference
像乐高一样的模块化RAG论文: [2407.21059] Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks
关于模块化RAG的实现和计划参见:Modular RAG - Part 2 · Issue #1811 · spring-projects/spring-ai
方案和实现
QuestionAnswer 基础的RAG
通过 org.springframework.ai.chat.client.advisor.QuestionAnswerAdvisor 这个增强实现,内置了一个提示词模版,作为 prompt
private static final String DEFAULT_USER_TEXT_ADVISE = """
Context information is below, surrounded by ---------------------
---------------------
{question_answer_context}
---------------------
Given the context and provided history information and not prior knowledge,
reply to the user comment. If the answer is not in the context, inform
the user that you can't answer the question.
""";
在这个 Advisor的 before中处理了如下内容
- Advise the system text.
- Search for similar documents in the vector store.
- Create the context from the documents.
- Advise the user parameters.
通过查询构造,向量库的相似检索和过滤,然后将文档信息补充到Prompt的模版中。
// 1. Advise the system text.
String advisedUserText = request.userText() + System.lineSeparator() + this.userTextAdvise;
// 2. Search for similar documents in the vector store.
String query = new PromptTemplate(request.userText(), request.userParams()).render();
var searchRequestToUse = SearchRequest.from(this.searchRequest)
.query(query)
.filterExpression(doGetFilterExpression(context))
.build();
List<Document> documents = this.vectorStore.similaritySearch(searchRequestToUse);
// 3. Create the context from the documents.
context.put(RETRIEVED_DOCUMENTS, documents);
String documentContext = documents.stream()
.map(Document::getText)
.collect(Collectors.joining(System.lineSeparator()));
// 4. Advise the user parameters.
Map<String, Object> advisedUserParams = new HashMap<>(request.userParams());
advisedUserParams.put("question_answer_context", documentContext);
AdvisedRequest advisedRequest = AdvisedRequest.from(request)
.userText(advisedUserText)
.userParams(advisedUserParams)
.adviseContext(context)
.build();
在 after中,将查询到的文档上下文,作为 meta的属性,放到 Response中

这里后续也可以直接在返回的Response中,获取到详细的引用文档信息。如果是 Stream模式,我们获取最后一个元素。
public Flux<ChatResponse> questionAnswerRagToChatResponse(String question) {
QuestionAnswerAdvisor questionAnswerAdvisor = new QuestionAnswerAdvisor(pgVectorStore);
return chatClient
.prompt()
.advisors(questionAnswerAdvisor)
.user(question)
.stream()
.chatResponse()
.doOnNext(resp -> {
if (resp.getResults().stream().anyMatch(result -> result != null && result.getMetadata() != null
&& "STOP".equals(result.getMetadata().getFinishReason()))) {
List<Document> documents = resp.getMetadata().get(RETRIEVED_DOCUMENTS);
if (documents != null) {
documents.forEach(d -> log.debug("retrieved document: {}", d.getText()));
}
}
})
.doOnError(throwable -> log.error("Error during questionAnswerRagToChatResponse: {}", throwable.getMessage()))
;
}
Multi Query Expansion (多查询扩展)
多查询扩展是提高RAG系统检索效果的关键技术。在实际应用中,用户的查询往往是简短且不完整的,这可能导致检索结果不够准确或完整。Spring AI提供了强大的多查询扩展机制,能够自动生成多个相关的查询变体,从而提高检索的准确性和召回率。
多查询扩展,将用户的 query交给大模型,生成相似的多个 query,以便更好地命中查询和文档库的数据。
以下是一个使用Spring AI的 MultiQueryExpand 实现多查询扩展的示例代码:
MultiQueryExpander queryExpander = MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.numberOfQueries(3)
.build();
List<Query> queries = expander.expand(new Query("How to run a Spring Boot app?"));
Query Transformation 查询转换
Query Translation (查询翻译)
TranslationQueryTransformer使用大型语言模型将查询转换为用于生成文档嵌入的嵌入模型支持的目标语言。如果查询已使用目标语言,则返回该查询时不会更改。如果查询的语言未知,则也会原封不动地返回该查询。当嵌入模型使用特定语言进行训练并且用户查询使用其他语言时,此转换器非常有用。
Query query = new Query("Hvad er Danmarks hovedstad?");
QueryTransformer queryTransformer = TranslationQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.targetLanguage("english")
.build();
Query transformedQuery = queryTransformer.transform(query);
CompressionQueryTransformer (压缩查询转换器)
CompressionQueryTransformer使用大型语言模型将对话历史记录和后续查询压缩为捕获对话本质的独立查询。当对话历史记录很长并且后续查询与对话上下文相关时,此转换器非常有用。
Query query = Query.builder()
.text("And what is its second largest city?")
.history(new UserMessage("What is the capital of Denmark?"),
new AssistantMessage("Copenhagen is the capital of Denmark."))
.build();
QueryTransformer queryTransformer = CompressionQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.build();
Query transformedQuery = queryTransformer.transform(query);
RewriteQueryTransformer 重写QueryTransformer
RewriteQueryTransformer使用大型语言模型重写用户查询,以便在查询目标系统(如矢量存储或 Web 搜索引擎)时提供更好的结果。当用户查询冗长、模棱两可或包含可能影响搜索结果质量的不相关信息时,此转换器非常有用。
Query query = new Query("I'm studying machine learning. What is an LLM?");
QueryTransformer queryTransformer = RewriteQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.build();
Query transformedQuery = queryTransformer.transform(query);
Context-aware Queries (上下文感知查询)
这个其实就是一段提示词,用于链接用户查询和文档检索结果,进而构造进模型的Request里
private static final PromptTemplate DEFAULT_PROMPT_TEMPLATE = new PromptTemplate("""
Context information is below.
--------------------- {context} ---------------------
Given the context information and no prior knowledge, answer the query.
Follow these rules:
1. If the answer is not in the context, just say that you don't know. 2. Avoid statements like "Based on the context..." or "The provided information...".
Query: {query}
Answer: """);
文档合并器(DocumentJoiner)
默认实现是 ConcatenationDocumentJoiner 就是聚合一下列表,如果有多查询扩展等。将多批文档做聚合。可以扩展这个 DocumentJoiner,实现自定义逻辑,例如通过其他方式排除一下文档,或者根据什么顺序将文档内容整合一下,或者根据可以根据检索的文档meta信息,找到原始的文档完整内容作为上下文等等。
@Override
public List<Document> join(Map<Query, List<List<Document>>> documentsForQuery) {
Assert.notNull(documentsForQuery, "documentsForQuery cannot be null");
Assert.noNullElements(documentsForQuery.keySet(), "documentsForQuery cannot contain null keys");
Assert.noNullElements(documentsForQuery.values(), "documentsForQuery cannot contain null values");
logger.debug("Joining documents by concatenation");
return new ArrayList<>(documentsForQuery.values()
.stream()
.flatMap(List::stream)
.flatMap(List::stream)
.collect(Collectors.toMap(Document::getId, Function.identity(), (existing, duplicate) -> existing))
.values());
}
聚合的增强顾问-检索增强顾问(RetrievalAugmentationAdvisor)
基于上述的RAG增强扩展库,大致设想和设计下优化后的RAG高级实现流程:
这里看一下 RetrievalAugmentationAdvisor 的源码。
public AdvisedRequest before(AdvisedRequest request) {
Map<String, Object> context = new HashMap<>(request.adviseContext());
// 0. Create a query from the user text and parameters.
Query originalQuery = new Query(new PromptTemplate(request.userText(), request.userParams()).render());
// 1. Transform original user query based on a chain of query transformers.
Query transformedQuery = originalQuery;
for (var queryTransformer : this.queryTransformers) {
transformedQuery = queryTransformer.apply(transformedQuery);
}
// 2. Expand query into one or multiple queries.
List<Query> expandedQueries = this.queryExpander != null ? this.queryExpander.expand(transformedQuery)
: List.of(transformedQuery);
// 3. Get similar documents for each query.
Map<Query, List<List<Document>>> documentsForQuery = expandedQueries.stream()
.map(query -> CompletableFuture.supplyAsync(() -> getDocumentsForQuery(query), this.taskExecutor))
.toList()
.stream()
.map(CompletableFuture::join)
.collect(Collectors.toMap(Map.Entry::getKey, entry -> List.of(entry.getValue())));
// 4. Combine documents retrieved based on multiple queries and from multiple data
// sources. List<Document> documents = this.documentJoiner.join(documentsForQuery);
context.put(DOCUMENT_CONTEXT, documents);
// 5. Augment user query with the document contextual data.
Query augmentedQuery = this.queryAugmenter.augment(originalQuery, documents);
// 6. Update advised request with augmented prompt.
return AdvisedRequest.from(request).userText(augmentedQuery.text()).adviseContext(context).build();
}
整体的流程如下,其实就是实现了上述提到的各个增强模块和扩展。
完整总结
这里Spring-ai对于RAG的支持和能力仍然在很初级的阶段。模块话RAG的思路仍然在建设过程中,不过整体的理念已经出来了,可以参见:
Modular RAG - Part 1 · Issue #1603 · spring-projects/spring-ai

这个是完整设计的流程。
且根据上述Issue的介绍,整体推进会包含:
- Pre-Retrieval 预取
- Query Transformation Modular RAG - Query Analysis #1703查询转换 Modular RAG - Query Analysis #1703
- Query Expansion Modular RAG - Query Analysis #1703
查询扩展 Modular RAG - Query Analysis #1703
- Retrieval 检索
- Post-Retrieval (only interfaces)检索后(仅限接口)
- Document Ranking Modular RAG: Orchestration and Post-Retrieval #1767 (a)文献排名 Modular RAG: Orchestration and Post-Retrieval #1767 (a)
- Document Selection Modular RAG: Orchestration and Post-Retrieval #1767 (a)文件选择 Modular RAG: Orchestration and Post-Retrieval #1767 (a)
- Document Compression Modular RAG: Orchestration and Post-Retrieval #1767 (a)
文档压缩 Modular RAG: Orchestration and Post-Retrieval #1767 (a)
- Augmentation 增加
- Orchestration (experimental)编排(实验性)
This issue will be updated as we progress with the design and implementation work.
随着设计和实现工作的进展,此问题将进行更新。
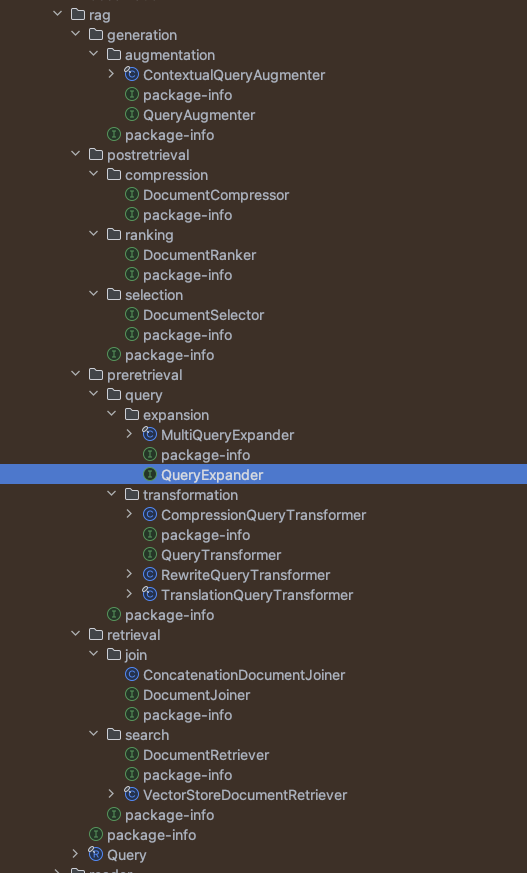
也可以在1.0.0-M5中看到如下包内容,很好的展示了目前的设计。